
明天从这里继续:
http://woodpecker.org.cn/diveintopython/object_oriented_framework/private_functions.html
分析这段代码
__author__ = "Mark Pilgrim (mark@diveintopython.org)"
__version__ = "$Revision: 1.3 $"
__date__ = "$Date: 2004/05/05 21:57:19 $"
__copyright__ = "Copyright (c) 2001 Mark Pilgrim"
__license__ = "Python"
import os
import sys
from UserDict import UserDict
def stripnulls(data):
"strip whitespace and nulls"
return data.replace("\00", " ").strip()
class FileInfo(UserDict):
"store file metadata"
def __init__(self, filename=None): #1. init
UserDict.__init__(self) #2. 用super关键字改造
self["name"] = filename #3. self
#4. 垃圾回收
class MP3FileInfo(FileInfo):
"store ID3v1.0 MP3 tags"
tagDataMap = {"title" : ( 3, 33, stripnulls),
"artist" : ( 33, 63, stripnulls),
"album" : ( 63, 93, stripnulls),
"year" : ( 93, 97, stripnulls),
"comment" : ( 97, 126, stripnulls),
"genre" : (127, 128, ord)}
def __parse(self, filename):
"parse ID3v1.0 tags from MP3 file"
self.clear()
try:
fsock = open(filename, "rb", 0)
try:
fsock.seek(-128, 2)
tagdata = fsock.read(128)
finally:
fsock.close()
if tagdata[:3] == 'TAG':
for tag, (start, end, parseFunc) in self.tagDataMap.items():
self[tag] = parseFunc(tagdata[start:end])
except IOError:
pass
def __setitem__(self, key, item):
if key == "name" and item:
self.__parse(item)
FileInfo.__setitem__(self, key, item)
def listDirectory(directory, fileExtList):
"get list of file info objects for files of particular extensions"
fileList = [os.path.normcase(f) for f in os.listdir(directory)]
fileList = [os.path.join(directory, f) for f in fileList \
if os.path.splitext(f)[1] in fileExtList]
def getFileInfoClass(filename, module=sys.modules[FileInfo.__module__]):
"get file info class from filename extension"
subclass = "%sFileInfo" % os.path.splitext(filename)[1].upper()[1:]
return hasattr(module, subclass) and getattr(module, subclass) or FileInfo
return [getFileInfoClass(f)(f) for f in fileList]
if __name__ == "__main__":
for info in listDirectory("/music/_singles/", [".mp3"]):
print "\n".join(["%s=%s" % (k, v) for k, v in info.items()])
print
python 2.2之前,你不可以直接子类化字符串、列表以及字典之类的内建数据类型。作为补偿,Python提供封装类来模拟内建数据类型的行为,比如UserString、UserList、UserDict。通过混合使用普通和特殊方法,UserDict类能十分出色地模仿字典。在Python 2.2和其后的版本中,你可以直接从dict内建数据类型继承。因此,下面的代码直接继承内建数据类型dict来代替上面代码继承UserDict的方式:
__author__ = "Mark Pilgrim (mark@diveintopython.org)"
__version__ = "$Revision: 1.2 $"
__date__ = "$Date: 2004/05/05 21:57:19 $"
__copyright__ = "Copyright (c) 2001 Mark Pilgrim"
__license__ = "Python"
import os
import sys
def stripnulls(data):
"strip whitespace and nulls"
return data.replace("\00", " ").strip()
class FileInfo(dict):
"store file metadata"
def __init__(self, filename=None):
self["name"] = filename
class MP3FileInfo(FileInfo):
"store ID3v1.0 MP3 tags"
tagDataMap = {"title" : ( 3, 33, stripnulls),
"artist" : ( 33, 63, stripnulls),
"album" : ( 63, 93, stripnulls),
"year" : ( 93, 97, stripnulls),
"comment" : ( 97, 126, stripnulls),
"genre" : (127, 128, ord)}
#6. Python类属性(类似Java静态变量) 和 Python数据属性(类似Java实例变量)
def __parse(self, filename):
"parse ID3v1.0 tags from MP3 file"
self.clear()
try:
fsock = open(filename, "rb", 0)
try:
fsock.seek(-128, 2)
tagdata = fsock.read(128)
finally:
fsock.close()
if tagdata[:3] == 'TAG':
for tag, (start, end, parseFunc) in self.tagDataMap.items():
self[tag] = parseFunc(tagdata[start:end])
except IOError:
pass
def __setitem__(self, key, item): #5. 专用类方法
if key == "name" and item:
self.__parse(item)
FileInfo.__setitem__(self, key, item)
def listDirectory(directory, fileExtList):
"get list of file info objects for files of particular extensions"
fileList = [os.path.normcase(f) for f in os.listdir(directory)]
fileList = [os.path.join(directory, f) for f in fileList \
if os.path.splitext(f)[1] in fileExtList]
def getFileInfoClass(filename, module=sys.modules[FileInfo.__module__]):
"get file info class from filename extension"
subclass = "%sFileInfo" % os.path.splitext(filename)[1].upper()[1:]
return hasattr(module, subclass) and getattr(module, subclass) or FileInfo
return [getFileInfoClass(f)(f) for f in fileList]
if __name__ == "__main__":
for info in listDirectory("/music/_singles/", [".mp3"]):
print "\n".join(["%s=%s" % (k, v) for k, v in info.items()])
print
#1. __init__方法:对象在调用__init__方法时已经被构造出来了,此时已经有一个对类的新实例的有效引用,因此不是构造函数。在继承结构中,Python沿着父类树走,发现有__init__(self, ...)则进行调用,并且除非显示在这个__init__(self, ...)中调用父类__init__(self, ...),否则不会自动调用。
class A(object):
def __init__(self):
print "A"
class B(A):
def __init__(self):
super(B, self).__init__()
print "B"
class C(A):
def __init__(self):
print "C"
class D(A):
pass
if __name__ == "__main__":
b = B()
c = C()
d = D()
输出:
A
B
C
A
#2. super关键字:
UserDict.__init__(self)
#使用super(ChildClass, self).fun()方式可以增加可维护性,但是父类必须继承object类
#i.e. super(FileInfo, self).__init__()
# 这里不能使用这种方式,因为父类UserDict没有集成object类
更详细地,参见这篇文章
在python的类中,经常会遇到要继承父类方法的情况。一般做法如下:
01 class A:
02 def __init__(self):
03 print 'Entry A'
04 print 'Leave A'
05
06 class B(A):
07 def __init__(self):
08 print 'Entry B'
09 A.__init__(self)
10 print 'Leave B'
11
12 if __name__ == "__main__":
13 b = B()
输出:
Entry B
Entry A
Leave A
Leave B
即在子类B中调用了父类A的__init__方法
但这种方式存在一个问题。那就是不利于维护,如果有多处需要调用父类A的方法(不一定是__init__方法,可能是更多的其他的方法)
一旦父类A的名称发生变更,那么,不得不遍历所有继承了A的子类,对调用的地方A的名称进行更改.super则可以很好的避免这些麻烦
再看下面的代码:
01 class A(object):
02 def __init__(self):
03 print 'Entry A'
04 print 'Leave A'
05
06 class B(A):
07 def __init__(self):
08 print 'Entry B'
09 super(B,self).__init__()
10 print 'Leave B'
11
12 if __name__ == "__main__":
13 b = B()
输出和上面的一样,可以看出,super会自动找到被继承的类的__init__方法并进行调用。在查找这个方式。遵循类的遍历规则。即按从下往
上,从左到右的顺序来进行
**注意:祖先类必须要继承 * object *,否则会报错.如下面的方式也是可以的:
01 class Base:
02 pass
03
04 class A(object,Base):
05 def fun(self):
06 pass
07
08 class B(A):
09 def fun(self):
10 super(B,self)
继续看代码:
01 class A(object):
02 def __init__(self,name):
03 print 'Entry A'
04 self.name = name
05 print self.name
06 print 'Leave A'
07
08 class B(A):
09 def __init__(self,name):
10 print 'Entry B'
11 super(B,self).__init__(name)
12 print 'Leave B'
13
14 if __name__ == "__main__":
15 b = B('cage')
输出:
Entry B
Entry A
cage
Leave A
Leave B
可见。带参数的调用和普通方式有细微的差别。除self参数外,其他的参数还是应该放在方法的里面的
#3. 参数self:每个类方法的第一个参数,包括 __init__,都是指向类的当前实例的引用。按照习惯这个参数总是被称为 self。在 __init__ 方法中,self 指向新创建的对象;在其它的类方法中,它指向方法被调用的类实例。尽管当定义方法时你需要明确指定 self,但在调用方法时,你不 用指定它,Python 会替你自动加上的。习惯上,任何 Python 类方法的第一个参数 (对当前实例的引用) 都叫做 self。这个参数扮演着 C++ 或 Java 中的保留字 this 的角色,但 self 在 Python 中并不是一个保留字,它只是一个命名习惯。虽然如此,也请除了 self 之外不要使用其它的名字,这是一个非常坚固的习惯。
#4. 垃圾回收:引用计数 --> 标记后清除(Python 2.0)
如果说创建一个新的实例是容易的,那么销毁它们甚至更容易。通常,不需要明确地释放实例,因为当指派给它们的变量超出作用域时,它们会被自动地释放。内存泄漏在 Python 中很少见。
例. 尝试实现内存泄漏
>>> def leakmem():
... f = fileinfo.FileInfo('/music/_singles/kairo.mp3') ......1
...
>>> for i in range(100):
... leakmem() ......2
1 每次 leakmem 函数被调用,你创建了 FileInfo 的一个实例,将其赋给变量 f,这个变量是函数内的一个局部变量。然后函数结束时没有释放 f,所以你可能认为有内存泄漏,但是你错了。当函数结束时,局部变量 f 超出了作用域。在这个地方,不再有任何对 FileInfo 新创建实例的引用 (因为除了 f 我们从未将其赋值给其它变量),所以 Python 替我们销毁掉实例。
2 不管我们调用 leakmem 函数多少次,决不会泄漏内存,因为每一次,Python 将在从 leakmem 返回前销毁掉新创建的 FileInfo 类实例。
对于这种垃圾收集的方式,技术上的术语叫做“引用计数”。Python 维护着对每个实例的引用列表。在上面的例子中,只有一个 FileInfo 的实例引用:局部变量 f。当函数结束时,变量 f 超出作用域,所以引用计数降为 0,则 Python 自动销毁掉实例。
在 Python 的以前版本中,存在引用计数失败的情况,这样 Python 不能在后面进行清除。如果你创建两个实例,它们相互引用 (例如,双重链表,每一个结点有都一个指向列表中前一个和后一个结点的指针),任一个实例都不会被自动销毁,因为 Python (正确) 认为对于每个实例都存在一个引用。Python 2.0 有一种额外的垃圾回收方式,叫做“标记后清除”,它足够聪明,可以正确地清除循环引用。
作为曾经读过哲学专业的一员,让我感到困惑的是,当没有人对事物进行观察时,它们就消失了,但是这确实是在 Python 中所发生的。通常,你可以完全忘记内存管理,让 Python 在后面进行清理。
最后再来看看“标记-清除”这种垃圾回收机制:
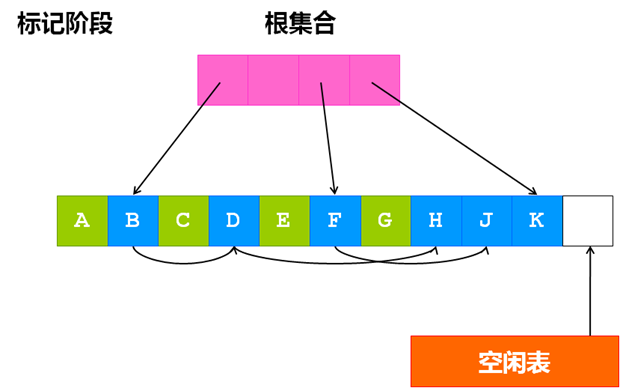
标记-清除(Mark-Sweep)算法依赖于对所有存活对象进行一次全局遍历来确定哪些对象可以回收,遍历的过程从根出发,找到所有可达对象,除 此之外,其它不可达的对象就是垃圾对象,可被回收。整个过程分为两个阶段:标记阶段找到所有存活对象;清除阶段清除所有垃圾对象。
标记阶段
清除阶段
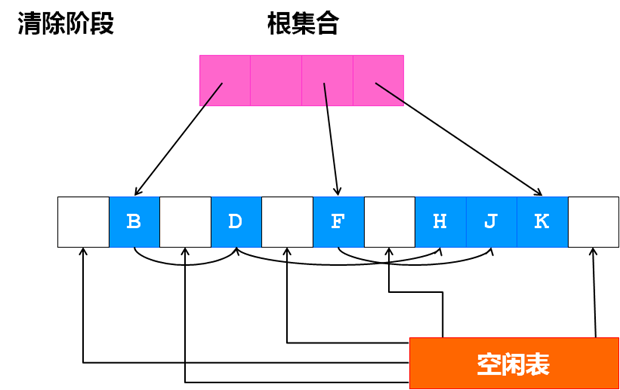
相比较引用计数算法,标记-清除算法可以非常自然的处理环形引用问题,另外在创建对象和销毁对象时时少了操作引用计 数值的开销。它的缺点在于标记-清除算法是一种“停止-启动”算法,在垃圾回收器运行过程中,应用程序必须暂时停止,所以对于标记-清除算法的研究如何减 少它的停顿时间,而分代式垃圾收集器就是为了减少它的停顿时间,后面会说到。另外,标记-清除算法在标记阶段需要遍历所有的存活对象,会造成一定的开销, 在清除阶段,清除垃圾对象后会造成大量的内存碎片。
#5. 专用类方法
专用方法的意义:提供一种方法,可以将非方法调用语法映射到方法调用上
def __getitem__(self, key): return self.data[key]
class FileInfo(UserDict):
def __getitem__(self, key): return self.data[key]
f = fileinfo.FileInfo("/music/_singles/kairo.mp3")
f["name"] 等价于 f.__getitem__("name")
def __setitem__(self, key, item): self.data[key] = itemf["genre"] = 32 相当于 调用f.__setitem__("genre", 31)
def __repr__(self): return repr(self.data)
__repr__ 是一个专用的方法,在当调用 repr(instance) 时被调用。repr 函数是一个内置函数,它返回一个对象的字符串表示。它可以用在任何对象上,不仅仅是类的实例。你已经对 repr 相当熟悉了,尽管你不知道它。在交互式窗口中,当你只敲入一个变量名,接着按ENTER,Python 使用 repr 来显示变量的值。自已用一些数据来创建一个字典 d ,然后用 print repr(d) 来看一看吧。
def __cmp__(self, dict):
if isinstance(dict, UserDict):
return cmp(self.data, dict.data)
else:
return cmp(self.data, dict)
__cmp__ 在比较类实例时被调用。通常,你可以通过使用 == 比较任意两个 Python 对象,不只是类实例。有一些规则,定义了何时内置数据类型被认为是相等的,例如,字典在有着全部相同的关键字和值时是相等的。对于类实例,你可以定义 __cmp__ 方法,自已编写比较逻辑,然后你可以使用 == 来比较你的类,Python 将会替你调用你的 __cmp__ 专用方法。
def __len__(self): return len(self.data)
__len__ 在调用 len(instance) 时被调用。len 是一个内置函数,可以返回一个对象的长度。它可以用于任何被认为理应有长度的对象。字符串的 len 是它的字符个数;字典的 len 是它的关键字的个数;列表或序列的 len 是元素的个数。对于类实例,定义 __len__ 方法,接着自已编写长度的计算,然后调用 len(instance),Python 将替你调用你的 __len__ 专用方法。
def __delitem__(self, key): del self.data[key]
__delitem__ 在调用 del instance[key] 时调用 ,你可能记得它作为从字典中删除单个元素的方法。当你在类实例中使用 del 时,Python 替你调用 __delitem__ 专用方法。
#6. Python类属性(类似Java静态变量) 和 Python数据属性(类似Java实例变量)
>>> class counter:
... count = 0 1
... def __init__(self):
... self.__class__.count += 1 2
...
>>> counter
<class __main__.counter at 010EAECC>
>>> counter.count 3
0
>>> c = counter()
>>> c.count 4
1
>>> counter.count
1
>>> d = counter() 5
>>> d.count
2
>>> c.count
2
>>> counter.count
2
| count 是 counter 类的一个类属性。 | |
| __class__ 是每个类实例的一个内置属性 (也是每个类的)。它是一个类的引用,而 self 是一个类 (在本例中,是 counter 类) 的实例。 | |
| 因为 count 是一个类属性,它可以在我们创建任何类实例之前,通过直接对类引用而得到。 | |
| 创建一个类实例会调用 __init__ 方法,它会给类属性 count 加 1。这样会影响到类自身,不只是新创建的实例。 | |
| 创建第二个实例将再次增加类属性 count。注意类属性是如何被类和所有类实例所共享的。 |
举例
# -*- encoding: gb18030 -*-
class counter:
count = 0 #只有类属性定义在这里
def __init__(self, str):
self.attr = str #数据属性定义在__init__(self, ...)中
self.__class__.count += 1
if __name__ == "__main__":
a = counter("hehe_a")
b = counter("hehe_b")
print counter.count #2
print a.count #2
print b.count #2
print a.attr #hehe_a
print b.attr #hehe_b



相关推荐
python面向对象练习题,资料,教育资料
本文实例讲述了Python面向对象之类和对象。分享给大家供大家参考,具体如下: 类和对象(1) 对象是什么? 对象=属性(静态)+方法(动态); 属性一般是一个个变量;方法是一个个函数; #类的属性 就是 类变量 #...
面向对象课件,价值200元,讲的挺详细的,能起到提纲挈领的作用
Python 面向对象编程,很简练的入门,通三观。
Python面向对象编程指南深入介绍Python语言的面向对象特性,全书分3个部分共18章。第1部分讲述用特殊方法实现Python风格的类,分别介绍了__init__()方法、与Python无缝集成—基本特殊方法、属性访问和特性及修饰符、...
Python面向对象编程指南深入介绍Python语言的面向对象特性,全书分3个部分共18章。第1部分讲述用特殊方法实现Python风格的类,分别介绍了__init__()方法、与Python无缝集成—基本特殊方法、属性访问和特性及修饰符、...
本文实例讲述了Python面向对象实现一个对象调用另一个对象操作。分享给大家供大家参考,具体如下: 我先总结一下python中的类的特点: 1.类中所有的方法的参数中都必须加self,并且是第一个参数 2.__init__方法用来...
python强大的面向对象能力,让你更好的理解python核心语法
Python 面向对象编程指南 .[美]Steven F.Lott, 只发布高清完整版!Python面向对象编程指南 高清完整版 pdf下载
这是我学习Python面向对象的时候自己总结的内容,很多都是从官方文档摘录的,对Python面向对象的编程有非常大的帮助。
python面向对象程序设计实践(初级) ——以《三国演义》中三英大战吕布为例 设计实现思路: 设计类 定义武器类:武器名,攻击力 定义人物类:继承武器类,姓名,生命值 设计函数简化对象的使用 延时函数:延时0.5秒...
python面向对象思维导图
Python面向对象学习思维脑图
python面向对象学习总结.pdf
分步逐一案例讲解,共18小节视频教程分九大部分来讲解,通俗易懂,跟学就能完成项目,并深入理解python面向对象编程思想。非常好的资源,物超所值!由于上传受限,本案例包含三部分。
这是2014年度辛星python的面向对象教程,希望大家能够喜欢。
Python面向对象编程指南.[美]Steven F.Lott(带详细书签),分成两个压缩包。本书由树莓派基金会资深软件开发工程师亲笔撰写,是学习在树莓派上编程的必备手册。即使你没有任何编程经验,也可以畅游树莓派的世界。本书...